Check this post in English 🇬🇧.
Introducción
DuckDB es una tecnología que ha ganado mucha atención en los últimos meses. Yo mismo descubrí su potencial completo hace unos meses cuando pude consultar algunos archivos parquet desde mi terminal de una manera muy simple.
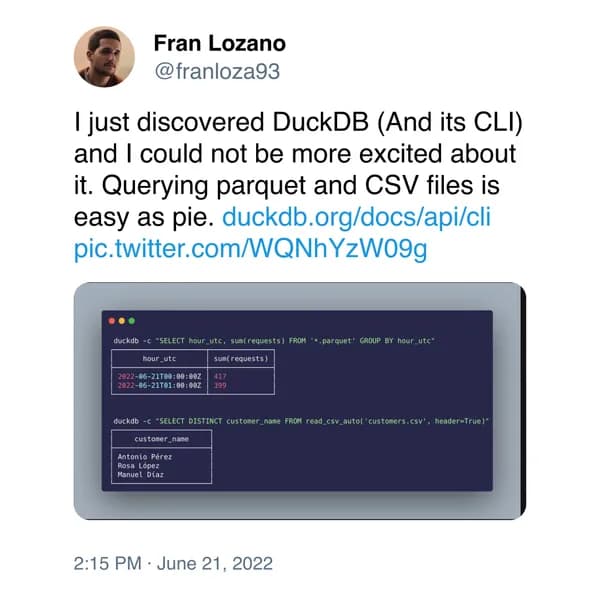
Acostumbrado a trabajar con archivos parquet en mi trabajo diario, usar la CLI de DuckDB aumentó significativamente mi productividad. Podía comprobar que el esquema de las tablas era correcto, agregar datos en cuestión de segundos e incluso leer los archivos directamente desde S3. Todo un descubrimiento.
¿Por qué es DuckDB tan revolucionario?
Además de su utilidad de línea de comandos para consultar CSV, Parquet y JSON, DuckDB permite análisis interactivos integrados y puede servir datos a herramientas de visualización interactiva.
Como explica Kojo en su blog, DuckDB llena el vacío en las bases de datos integradas para el procesamiento analítico en línea (OLAP).

Ya no es necesario usar un almacén de datos independiente como Snowflake o BigQuery para desarrollar una aplicación que realice consultas analíticas complejas. Con DuckDB tienes la simplicidad de SQLite y la funcionalidad de Snowflake, en tu máquina local. Esto abre un mundo completamente nuevo de posibilidades para desarrollar aplicaciones de datos con herramientas de código abierto.
Esta tendencia hacia la creación de aplicaciones de datos se ha reflejado recientemente este año con la adquisición de Streamlit por Snowflake. DuckDB no solo se limita al desarrollo de aplicaciones de datos integradas, sino que también se puede usar para prototipos rápidos con herramientas como Streamlit, y luego migrar a Snowflake u otro almacén de datos para servir una aplicación web.
Además, dbt tiene integración con DuckDB, y créeme, es rapidísimo. Esto te permitirá usar dbt para transformar datos sin tener que ejecutar una base de datos local como PostgreSQL. Además, dbt tiene la capacidad de hacer snapshots de tus datos, lo que te permite mantener el historial de cambios en una tabla para analizar los datos a lo largo del tiempo. Incluso puedes consultar datos desde DataGrip (o PyCharm Professional), lo que lo hace especialmente atractivo para el desarrollo de aplicaciones de datos.
Caso de uso
A mediados del año, sentí la necesidad de comprar mi primer coche. En algunas grandes ciudades como Madrid, la regulación para coches contaminantes es cada vez más estricta, así que opté por comprar un coche híbrido. Pero había un problema: el mercado de segunda mano para coches híbridos no está tan desarrollado como el mercado de combustibles tradicionales, lo que significaba que no había muchas buenas oportunidades. Supuse que había una falta de oferta de coches híbridos de segunda mano, así que quise analizarlo y ver si era posible encontrar oportunidades.
Uno de los principales portales de venta de coches de segunda mano en España es coches.net. Usando un script en Bash, descargué los datos y los analicé con Pandas y Plotly.
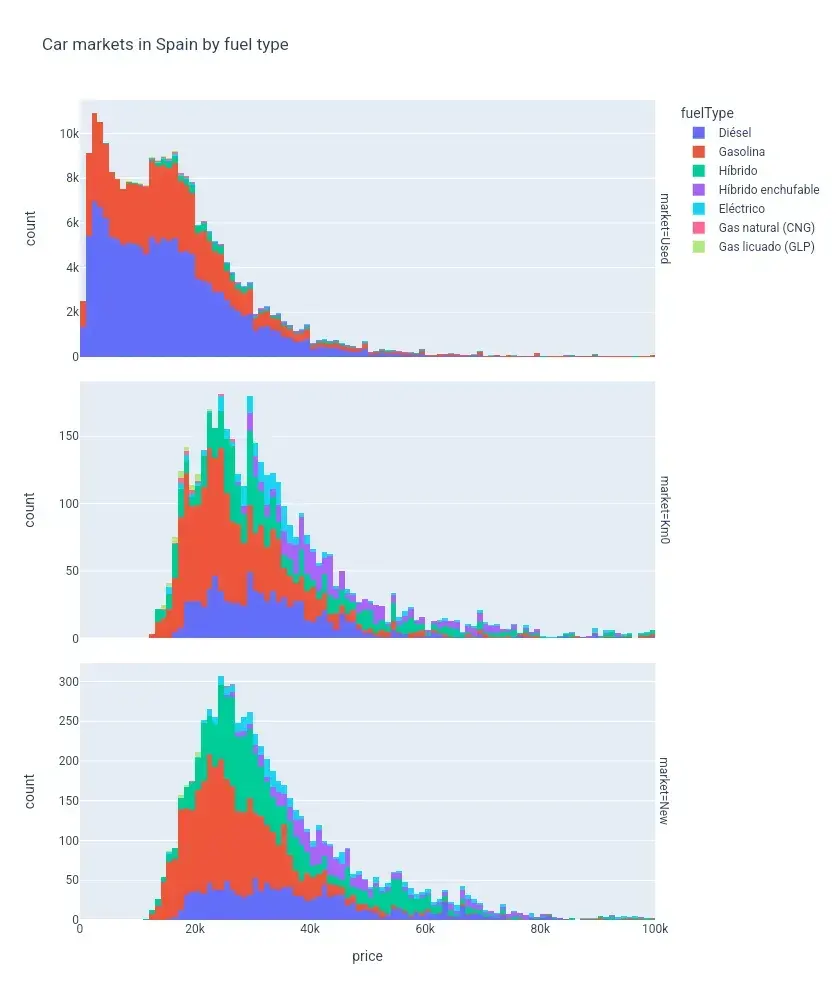
Aquí pude ver que el porcentaje de coches híbridos nuevos (verde y morado, segundo y tercer gráfico), era mayor que el de coches híbridos usados (primer gráfico), que apenas llegaba al 5%.
En este punto, quería ir un poco más allá y ver si era posible construir una aplicación para rastrear el cambio en los precios de los coches a lo largo del tiempo. Logré convencer a mi amigo Jorge, que estaba interesado en comprar un vehículo (una moto en lugar de un coche), y le presenté un diseño de cómo quería que fuera la aplicación.
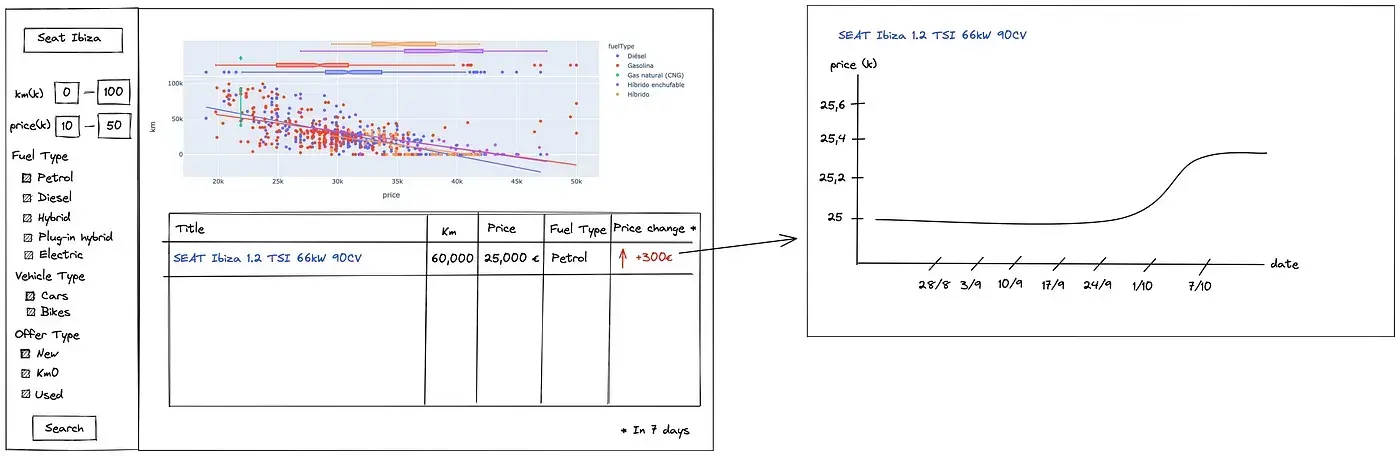
Jorge, siempre dispuesto a aprender y trabajar en cosas nuevas, estuvo de acuerdo, así que nos pusimos manos a la obra.
Desarrollo de la aplicación
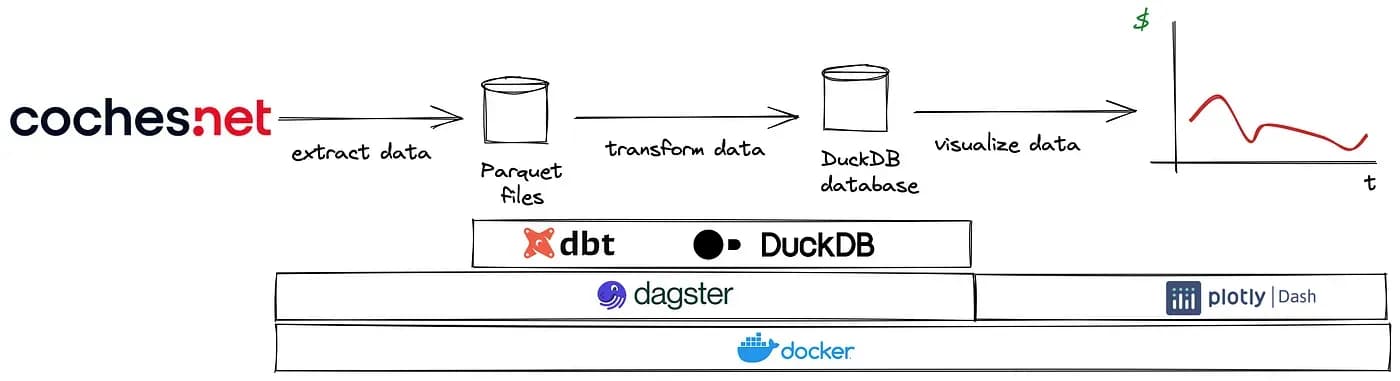
Cuando comenzamos, solo teníamos un script en Bash y un cuaderno de Jupyter con algunos gráficos, pero necesitábamos crear una aplicación interactiva. Fue entonces cuando decidimos usar DuckDB como la base de datos de la aplicación debido a su velocidad y simplicidad.
Además, necesitábamos tener un snapshot de los precios cada día para poder graficar su evolución y detectar oportunidades. Con estos requisitos, decidí usar Dagster en lugar de Airflow porque quería probar esta plataforma, que también estaba bien integrada con dbt y Jorge ya tenía experiencia con ella. Decidimos usar dbt para la creación de las tablas que iban a ser leídas por la aplicación, así como los snapshots.
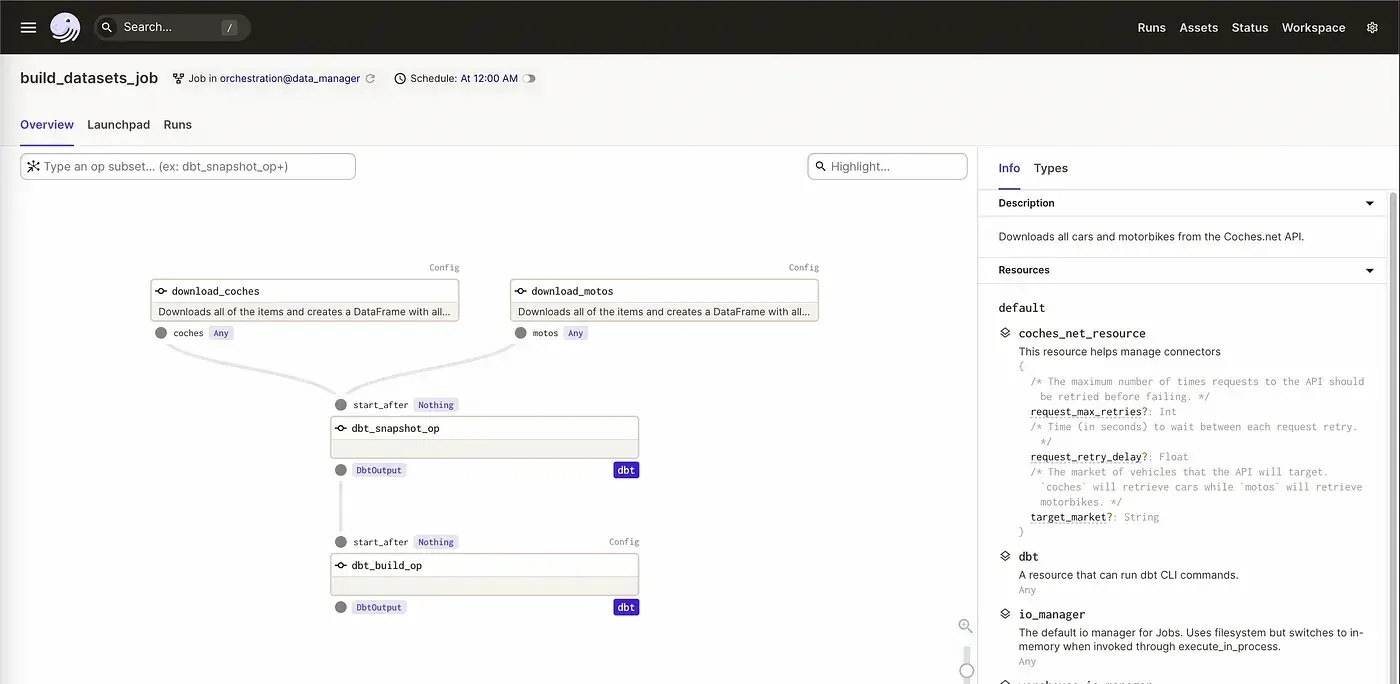
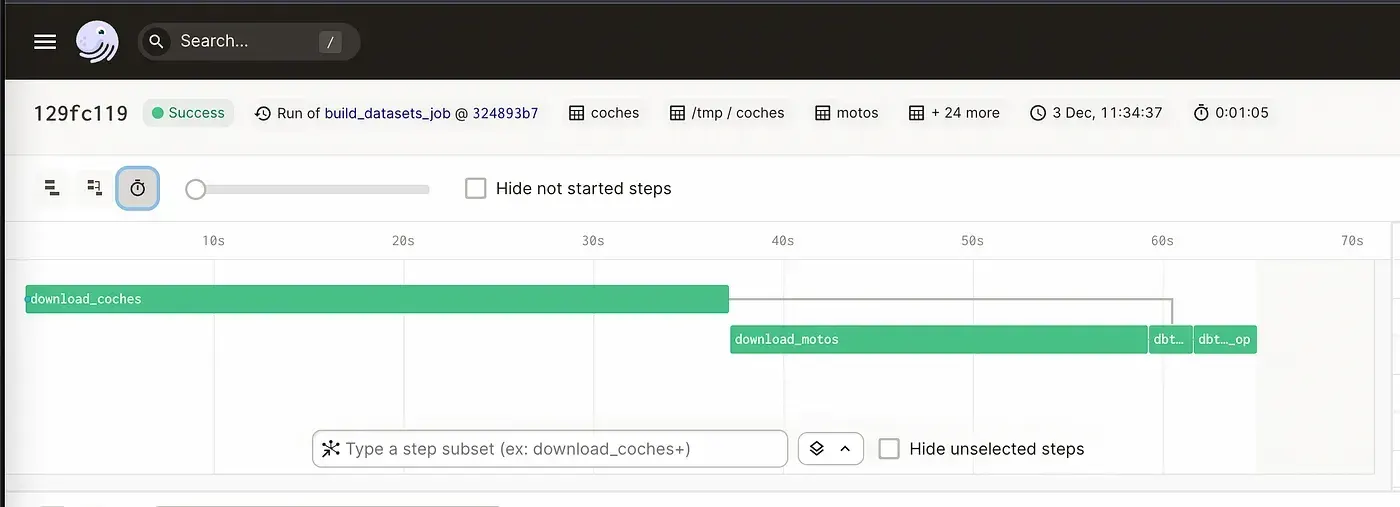
Migramos el script de Bash a un módulo de Python y Jorge lo adaptó para también descargar el conjunto de datos de motos. Usando macros de dbt, reutilizamos mucho código en el modelado de datos, ya que el modelo era prácticamente idéntico. Las dependencias entre tareas las definimos en Dagster, creando un job.
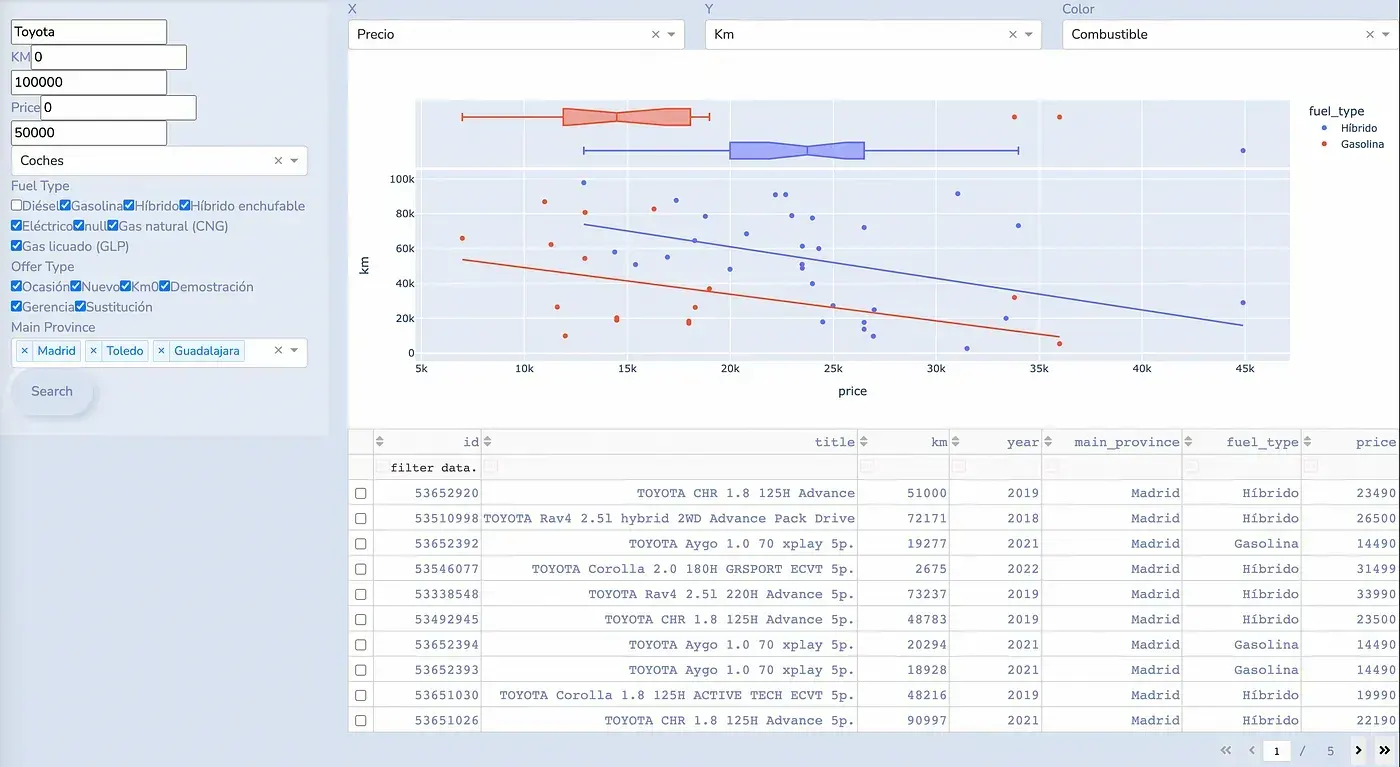
Jorge se encargó del desarrollo de la aplicación de visualización. Para este propósito, utilizó Dash, un framework para construir aplicaciones de datos en Python. Con esta herramienta, pudimos explorar desde diferentes perspectivas el mercado de coches y motos en España, y rastrear los cambios en los precios.
Finalmente, preparamos la aplicación para que pudiera desplegarse con un solo comando usando Docker Compose. También intentamos desplegarla en una máquina EC2 para que actualizara los datos de la base de datos diariamente de manera automatizada, pero nos encontramos con un problema: las IPs de AWS estaban bloqueadas en coches.net, por lo que no pudimos automatizar este último paso.
Conclusión
Gracias a las herramientas de código abierto y especialmente a DuckDB, fue posible construir una aplicación de datos de manera sencilla. También descubrí que el mercado de segunda mano para coches híbridos en España aún tiene que crecer y carece de oferta en comparación con los coches de combustible, lo que hacía difícil encontrar buenas oportunidades.
Puedes encontrar el código completo de la aplicación en Github. ¡Hasta pronto!