Check this post in English 🇬🇧.
Todo empezó con una aplicación que hice para mostrar estadísticas del circuito de carreras populares que se celebra cada año en Cuenca. Hablé de ello en este post.
El proceso de actualización de los datos era casi automático. Se extraen los datos del cronometrador (Cronomancha).
Se transforman usando una query (no quise usar dbt porque era una dependencia más y realmente no se necesitaba).
Se actualiza la base de datos que está alojada también en Git (pesa sólo 4MB, no es un problema).
Se suben los cambios a la rama main y Netlify se encarga de desplegar la web. Ya está. Fácil.
Un proceso casi automático
Sólo hay un PERO. Hay un pequeño paso que es manual. El cronometrador pone el nombre que se le ocurre para las carreras, el cual puede no coincidir con el nombre que viene en el calendario oficial especificado en el reglamento.
Aquí un ejemplo:
- Calendario oficial:
XVI 10K LA PITA - Nombre de la carrera especificado por el cronometrador:
XVI 10K LA PITA - 2025
Otro ejemplo en el que se ve que no hay un patrón claro:
- Calendario oficial:
X CARRERA POPULAR DE LA GUITARRA ESPAÑOLA - Nombre de la carrera especificado por el cronometrador:
CASIMARRO - CIRCUITO CCPP 2025
Y así con unas cuantas carreras más.
Como veis, un “fuzzy matching” se queda corto aquí. El quid de la cuestión es que se necesita contexto (como saber cómo se ha llamado la carrera en años anteriores) para resolverlo.
Por esta razón, mantengo un fichero en forma de CSV que resuelva esta relación. Este fichero relaciona los nombres de las carreras especificados por el cronometrador con el calendario que especifica su ubicación, fecha y número de carrera. Al principio del año, conozco el orden y la localización de todas las carreras gracias al calendario. Así, puedo rellenar todas las filas del CSV, excepto el nombre “oficial” de la carrera, que no lo sé hasta que el cronometrador publica los resultados en su web.
La importancia del contexto
El contexto para resolver este problema se puede extraer del propio fichero de mapeo, que ya contiene cómo se ha hecho esa clasificación para otros años. Si yo veo que el año pasado, la carrera de “La Pita” fue en El Herrumblar, es muy probable que este año sea en el mismo lugar. Si veo que el nombre de la carrera contiene “CASIMARRO”, es muy probable que sea en Casasimarro, incluso si otros años se ha llamado “Carrera popular de la guitarra española”. ¿Veis por dónde voy, no? Es un problema que se puede resolver con un poco de contexto, pero es difícil resolverlo de manera algorítmica.
Y es aquí donde entran en juego los LLMs.
Para resolverlo, quise que un LLM fuera el encargado de realizar esta tarea, obteniendo el nombre de las carreras realizadas en el año presente después de actualizar la base de datos, y tratando de rellenar el hueco del nombre que hay en el CSV.
Domando al LLM con un buen prompt
Para ello, usé OpenRouter porque no sabía qué modelo usar (es una tarea a priori sencilla, no se necesita un modelo de LLM avanzado), y quería tener la flexibilidad de poder cambiar el modelo en el futuro por otro más barato que siguiera funcionando bien.
Después de una horilla de vibe coding, lo tenía funcionando. Increíble. No quiero entrar mucho en detalles técnicos sobre este proceso, pero os lo resumo en unos cuantos puntos:
- No escribí una sola línea de código. Todo fue interacción con el agente de IA de Cursor. Usé Gemini-2.5 Pro, que últimamente me da muy buenos resultados.
- Si no pones buenos guardarraíles al prompt, el LLM tiende a alucinar. Gran parte de mi tiempo lo dediqué a iterar con la IA para dar reglas claras en el prompt y evitar que se inventara nombres de carreras que no habían sucedido aún. También fue clave dar las suficientes pistas en el prompt para que entendiera que las ubicaciones en el nombre de la carrera eran relevantes. Si una carrera se llamaba
XVII SUBIDA A LOS MOLINOS DE MOTA DEL CUERVO, es muy probable que sea en Mota del Cuervo, y no en Cuenca, por ejemplo. Si la IA no estaba segura, había también que dar instrucciones claras para que, en caso de duda, devolvieranull, indicando que no encontró una coincidencia. - Opté por construir un prompt más amplio incluyendo datos históricos del mapeo en lugar de llamar al LLM por cada fila a rellenar del CSV. Las ventanas de contexto de los LLMs son cada vez más amplias, y cuando no manejas grandes volúmenes de datos, creo que es mejor darle todo el contexto a la vez que hacer múltiples llamadas más pequeñas.
- Definí un formato de salida claro para el LLM: un array JSON de objetos, que permitiera la actualización del CSV de manera programática.
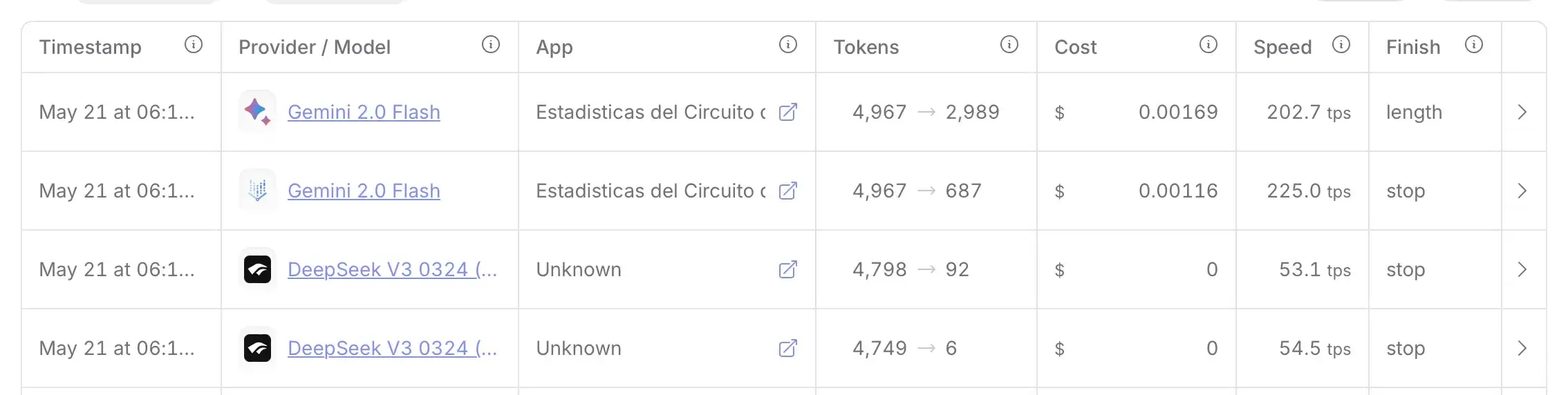
- Probé al principio con el modelo gratis de DeepSeek V3, pero no me dio buenos resultados. Finalmente me quedé con Gemini 2.0 Flash, que lo resolvía correctamente, rápido y con un coste muy bajo por llamada.
Mi asistente de IA en Cursor fue esencial en este proceso. Yo describía el problema (“El LLM no está priorizando la ubicación lo suficiente”), y sugería modificaciones a la estructura o redacción del prompt. Luego aplicábamos los cambios directamente en el script y probábamos de nuevo. Fue un proceso completamente natural de iteración y mejora, como si tuviera un programador a mi lado ayudándome con este proceso.
Si queréis ver el resultado, lo podéis encontrar aquí. Este script contiene el prompt y el código de actualización del CSV. El bot ya ha creado su primera Pull Request, y confío en ponerlo en modo completamente automático. Esto será posible una vez valide en las próximas semanas que realiza correctamente la tarea.
Notas finales
Este proceso de vibe coding fue más que un simple ejercicio de codificación. Fue un proceso iterativo con un compañero de viaje que me entiende y me ayuda a resolver un problema. Una inmersión profunda en la ingeniería de prompts, y una constatación de que la IA va a habilitar casos de uso que antes no eran tan triviales de resolver de manera algorítmica. Si tienes una tarea que implique un problema de “fuzzy matching”, o el mantenimiento de un mapeo de datos que requiera tener algo de contexto, creo que merece la pena considerar usar un LLM guiado con un prompt bien estructurado. Por mi parte, estoy convencido de que este compañero de viaje ha venido para quedarse y me va a acompañar en los próximos desafíos a los que me enfrente en el futuro.