Desde hace unos años, me interesan los datos abiertos y la transparencia del sector público. Una persona de referencia para mí es Jaime Gómez-Obregón, quien hace un fantástico trabajo dando visibilidad a la administración pública con herramientas como Contratosdecantabria.es.
En 2021, inspirado por su trabajo, desarrollé una aplicación para procesar los contratos de la Comunidad de Madrid y exponerlos de una manera similar. También hice ingeniería inversa de la API de la web de contratos de la Comunidad de Madrid para poder reusar su frontend. Compartí mi trabajo con Jaime en Twitter, y me comentó que su intención era liberar el código de su aplicación web para que otras personas pudieran usarla, pero esto no llegó a suceder. Como no estaba dispuesto a publicar una web copiada con código que no era libre, dejé el proyecto en espera.
Un nuevo proyecto
Unos años después, con el auge del vibe coding, decidí retomar este proyecto. Quise rehacer el frontend desde cero, pero con un matiz: quería ver si podía hacerlo sin necesidad de una API y una base de datos (la API que desarrollé usaba Elasticsearch). Enseguida me topé con el primer problema: el portal desde el que se servían los datos había cambiado y mi viejo script de extracción ya no funcionaba, así que tuve que escribir uno nuevo.
El nuevo buscador no exponía los datos en una API, sino que devolvía los resultados directamente en el HTML. Solo se podía acceder a los datos detallados entrando en la página de cada contrato, y descargarlos uno por uno era inviable (hay casi 2 millones de contratos cerrados solo en los últimos 5 años). El buscador también ofrecía la opción de descargar un CSV desde la búsqueda avanzada, así que opté por esta vía para obtener los datos de forma masiva.
Aquí me encontré con otro obstáculo. El sistema de descarga de CSV funcionaba con un sistema de cookies, claves anti-bot y un captcha matemático (bastante simple, para ser honesto). Le pedí a Cursor que desarrollara un script para poder descargar el CSV, proporcionándole un fichero HAR que contenía los datos de las peticiones y respuestas de mi navegador.

La IA optó por usar BeautifulSoup, una librería de Python para extraer datos de HTML. Tras varias iteraciones, el script se atascó y solo obtenía un error 500 del servidor. En este punto, decidí cambiar de enfoque y le pedí a la IA que usara una librería que usara un navegador, ya que creía que el flujo era demasiado complejo para hacerlo con peticiones simples. La IA eligió PlayWright, una herramienta que no había usado antes (yo conocía Selenium, que también funcionaba bien).
PlayWright tiene una funcionalidad muy útil que permite grabar las interacciones en el navegador. Tras grabar el flujo e iterar con la IA, especialmente en la parte de resolución del captcha, logré tener un script funcional para descargar un CSV con filtros de búsqueda. A partir de ahí, tuve que desarrollar otro para descargar todo el histórico de datos, iterando por mes. El buscador limitaba la descarga a 50.000 registros por CSV, así que tuve que pedirle a la IA que desarrollara una lógica para dividir la descarga por semana o día cuando se superara el límite, ya que la web no devolvía ningún error.
De la decepción a la solución
Me decepcionó un poco ver que la información del CSV era bastante limitada. Apenas contenía información específica sobre los contratos (título, n.º de expediente y referencia), por lo que no tenía mucho sentido crear un buscador de contratos individuales. Además, faltaba la información sobre los licitadores. Estos datos no solo no estaban en el CSV, sino que tampoco aparecían en el portal de contratos. Se encontraban en una tabla dentro de uno de los múltiples PDF adjuntos en cada contrato.
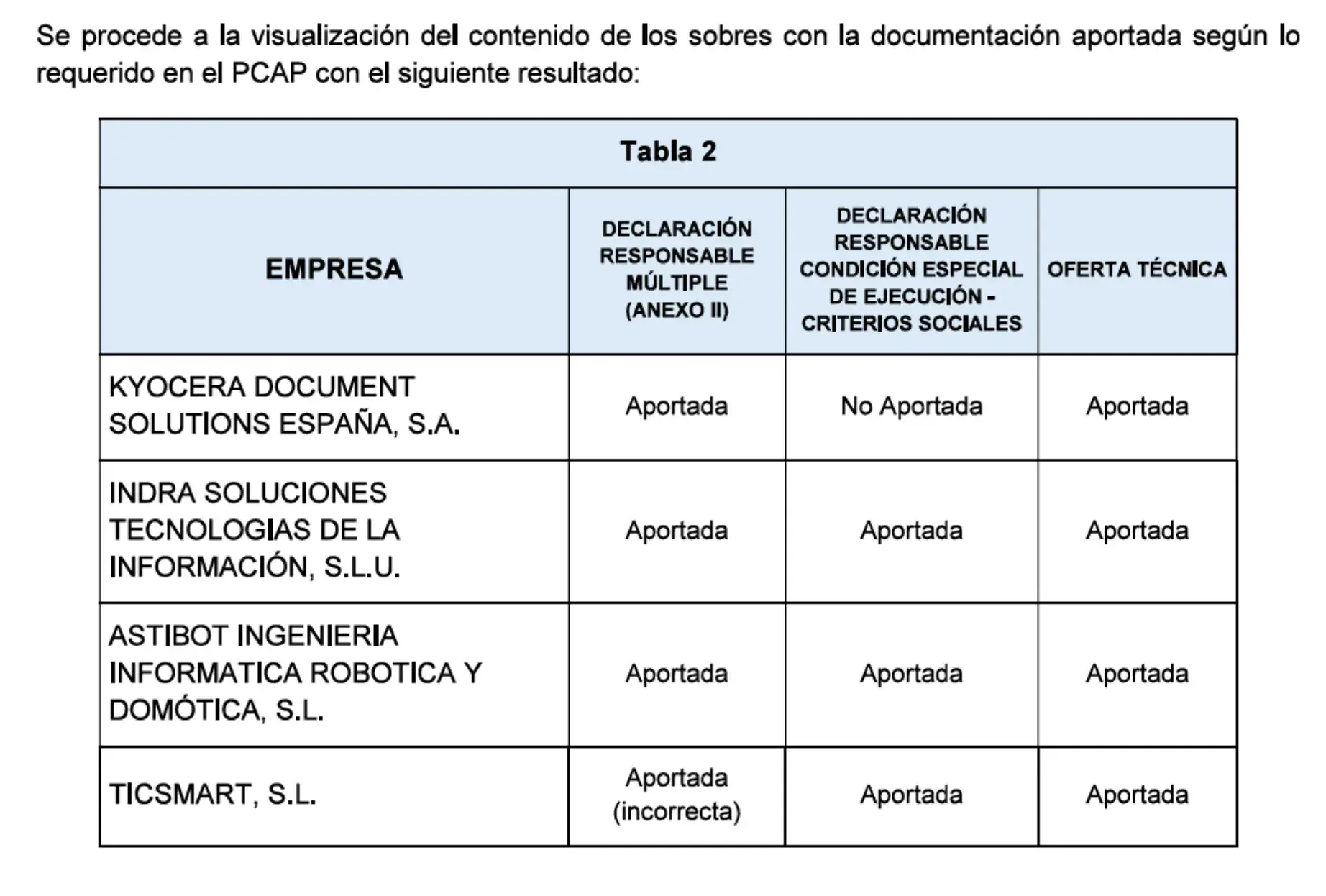
Jaime ha hablado en numerosas ocasiones sobre el uso del PDF para ocultar información que la ley exige publicar. Sin estos datos, la aplicación perdía mucho potencial (por ejemplo, ver con quién suele competir una empresa). Por último, el hecho de que el Registro Mercantil no sea abierto en España me impedía cruzar los datos de los administradores de las empresas con otras fuentes, como las listas electorales. Existen herramientas de pago fantásticas como LibreBOR, pero extraer los datos de más de 26.000 empresas se me iba de presupuesto.
Si los captchas, las claves anti-bot, los PDF y la falta de una API abierta no eran obstáculos suficientes, resultó que los datos del CSV eran un desastre. Aquí un par de ejemplos:
- A veces, los contratos se dividían en diferentes lotes, que podían ser adjudicados a empresas diferentes. Esta división no estaba correctamente reflejada en el CSV (por ejemplo, no se incluía el número de lote). Además, la información del contrato «padre» aparecía en blanco para los lotes que no eran el primero, por lo que era imposible relacionar directamente a los adjudicatarios con el contrato inicial. Para resolver esto, tuve que aplicar una transformación de forward fill, que requería añadir el número de fila al CSV para conservar el orden original en la base de datos.

-
Las fechas tenían un formato legible por humanos (p. ej.,
27 de marzo del 2024), pero no seguían un estándar ISO. -
Los nombres de las empresas eran incorrectos en numerosos contratos. Por ejemplo, en este contrato de 74 millones de euros, el nombre de la empresa está mal escrito.
Para solventar estos y otros problemas, iteré mucho con la IA, usando el servidor MCP de DuckDB. Esto permitía a la IA no solo implementar transformaciones para procesar los datos, sino también validar que los resultados eran los esperados. Aquí podéis encontrar las transformaciones finales que tuve que hacer para obtener una tabla con los datos refinados.
Llegado a este punto, decidí publicar una aplicación web con un pequeño buscador de empresas y algunas estadísticas. Podéis encontrar la aplicación aquí y el código en GitHub. La interfaz no es visualmente atractiva, pero no quise dedicarle más tiempo, consciente de la limitada funcionalidad de la aplicación.
La aplicación web usa Evidence (un framework que ya he usado para otras aplicaciones) y no tiene backend: es un sitio estático alojado en Netlify. Tampoco quise automatizar el refresco de datos y el despliegue continuo, ya que no sé qué interés puede generar, y eso implicaría gestionar almacenamiento en la nube y trabajo adicional.
Reflexiones finales
Viendo el proyecto en perspectiva, me doy cuenta de que la parte técnica no fue la más complicada. La IA es capaz ya de asistir de manera muy eficaz en la elaboración de scripts para la extracción y transformación de datos. La verdadera batalla fue contra las barreras, a veces invisibles, que las propias administraciones levantan. Un portal que parece diseñado para limitar los datos que te puedes descargar, el uso deliberado de formatos como el PDF para enterrar información clave y, para colmo, datos de una calidad cuestionable. Cada uno de estos obstáculos aleja al ciudadano de la información que, por ley, es suya. La transparencia no es colgar un PDF; es ofrecer datos de forma clara, accesible y reutilizable.
Pero esta historia también tiene una cara positiva. A pesar de todo, la tecnología nos da herramientas cada vez más potentes. Este proyecto, con todas sus dificultades, no habría sido igual de rápido sin la ayuda de la IA. Estamos viviendo un momento increíble para construir, y creo que la inteligencia artificial puede dar el empujón definitivo para que desarrolladores independientes como yo sigamos creando herramientas que, poco a poco, fuercen una mayor transparencia en el sector público. El camino es frustrante, pero las posibilidades son enormes.